


人工智能最近很火,能写论文、能写代码,还能作图,它们可以模拟人类的思维方式和学习能力,并完成一些复杂的任务。但由于中文语言理解的问题,适合中国人自己的人工智能到底怎么样?
相对国外来说,中文的人工智能模型在技术领域上面临几个难点。首先,中文是一种复杂的语言,其中包含了大量的同音字、多音字、缩写、繁体字、词语搭配等,这给模型的语言理解带来了很大的挑战。其次,中文的语义结构比较复杂,包括句子结构、词语含义、上下文逻辑等多个方面。人工智能模型需要通过大量的数据和知识来进行语义分析和推理,这也增加了模型的训练难度。然后就是面临大规模数据处理,中文数据集通常比较大,需要消耗大量的计算资源和时间来进行训练和预测。

5月9日,中文通用大模型综合性评测基准SuperCLUE正式发布,这是中文领域的权威测评社区,它针对市面几款主流人工智能模型进行了评测,该基准测试主要关注以下问题:中文大模型在不同任务上的表现如何?与国际代表性模型相比,中文大模型的表现达到了何种程度?中文大模型与人类表现相比如何?

评测的内容包含,基础能力:包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。以及专业能力,中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。还有中文特性能力,针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
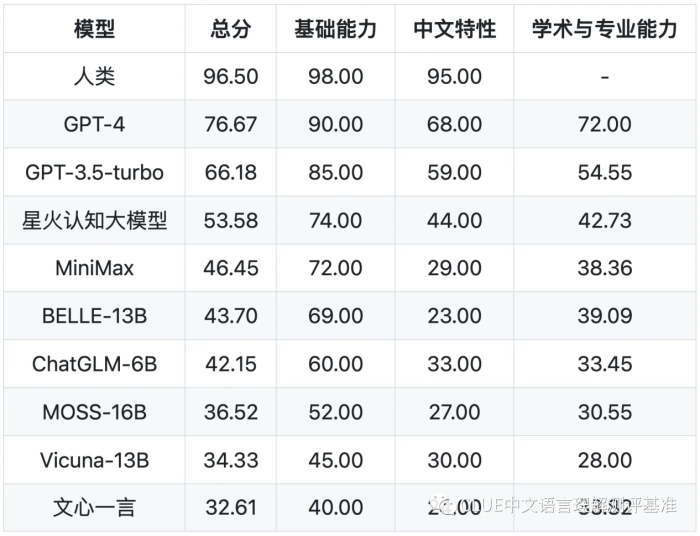
该机构利用SuperCLUE测试基准,对市面上主流的支持中文的通用大模型进行了评测与排名。从排名中我们可以看出,GPT-4一骑绝尘,已经非常接近人类的能力。国产大模型中讯飞科技研发的星火认知大模型总排名第三,国内排名第一。
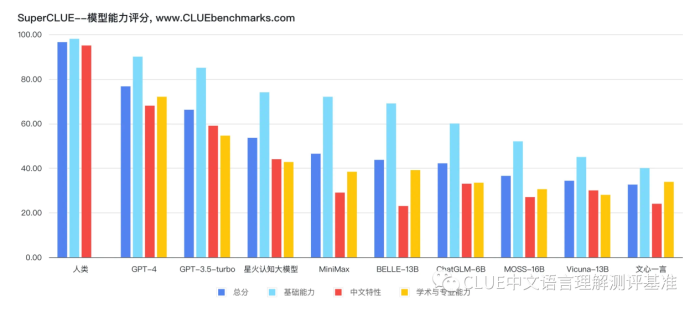
星火认知大模型有何实力?在国内各大人工智能大模型下,排名第一?在5月6日科大讯飞星火认知大模型发布会上,科大讯飞董事长刘庆峰现场“真机实测”演示了文本生成、语言理解、知识问答、数学能力等核心能力,星火大模型表现的“很睿智”,不少网友表示感到惊艳、效果超预期。

大模型的背后是认知智能,科大讯飞作为人工智能国家队之一,多年来一直深耕认知智能领域,有能力推出自主研发的国产大模型。从科大讯飞的发展历程来看,其在2014年就提出讯飞超脑计划,目标就是让机器能理解会思考,在2022年进一步提出讯飞超脑2030计划,进一步深耕认知智能。并且承办国家语言及语言国家重点实验室、认知智能国家重点实验室以及国家新一代人工智能开发创新平台,可谓是AI国家队的代表。仅过去一年在认知智能领域就有10+项世界冠军。

总的来说,中国的人工智能大模型已经取得了很大的进展,并在很多领域都有着广泛的应用。但是我们也需要认识到,由于技术本身的限制和人类认知的局限性,现在的人工智能模型还存在着一些问题和限制。未来,我们需要继续探索和研究人工智能模型。也期待国内的涌现更多的企业,让世界看到我们走在科技、智能的最前端。








